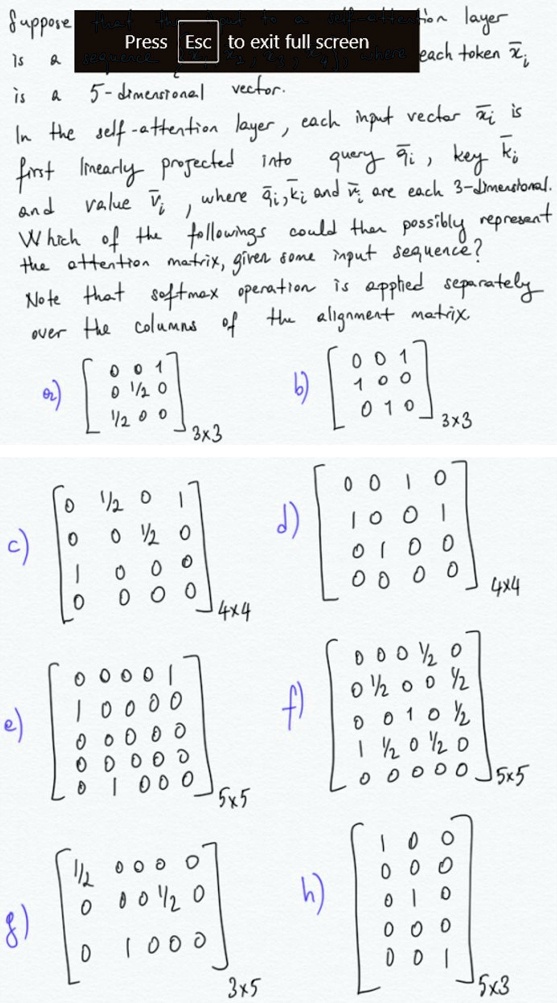
Suppose that the input to a self-attention layer is a 5-dimensional vector.
In the self-attention layer, each input vector �ar{x} _(i) is first linearly projected into query �ar{q}_(i), key �ar{k}_(i) and value �ar{v}_(i), where �ar{q}_(i), �ar{k}_(i) and �ar{v}_(i) are each 3-dimensional.
Which of the followings could there possibly represent the attention matrix, given some input sequence?
Note that softmax operation is applied separately over the columns of the alignment matrix.
a) [[0,0,1],[0,(1)/(2),0],[(1)/(2),0,0]]_(3x3)
b) [[0,0,1],[1,0,0],[0,1,0]]_(3x3)
c) [[0,(1)/(2),0,1],[0,0,(1)/(2),0],[1,0,0,0],[0,0,0,0]]_(4x4)
d) [[0,0,1,0],[1,0,0,1],[0,1,0,0],[0,0,0,0]]_(4x4)
e) [[0,0,0,0,1],[1,0,0,0,0],[0,0,0,0,0],[0,0,0,0,0],[0,1,0,0,0]]
f) [[1,0,0],[0,0,0],[0,1,0],[0,0,0],[0,0,1]]_(5x3)