In [ ]: def evaluate_knn_classifier(X_train, y_train, X_test, y_test, best_k):
Evaluates the KNN classifier on the test set with the given best 'K' value.
Parameters:
X_train: Training data features.
y_train: Training data labels.
X_test: Test data features.
y_test: Test data labels.
best_k: The optimal/best number of neighbors.
Returns:
accuracy, precision, recall, true_positives, true_negatives: Evaluation metrics.
return accuracy, precision, recall, true_positives, true_negatives
# Usage example:
# accuracy, precision, recall, true_positives, true_negatives = evaluate_knn_classifier(X_train, y_train, X_test, y_test, best_k)
# print(f"Accuracy: {accuracy}, Precision: {precision}, Recall: {recall}, True Positives: {true_positives}, True Negatives: {true}
#2 Introduction to Support Vector Machines (SVM)
Support Vector Machines (SVM) represent a powerful and versatile class of supervised machine learning algorithms, used for both classification and regression tasks. At its core, SVM seeks to find the optimal separating hyperplane between different classes in the feature space. This hyperplane is chosen to maximize the margin between the closest points of the classes, which are known as support vectors. This distinctive approach to classification enables SVM to excel in a wide range of complex datasets, including those where the data points are not linearly separable.
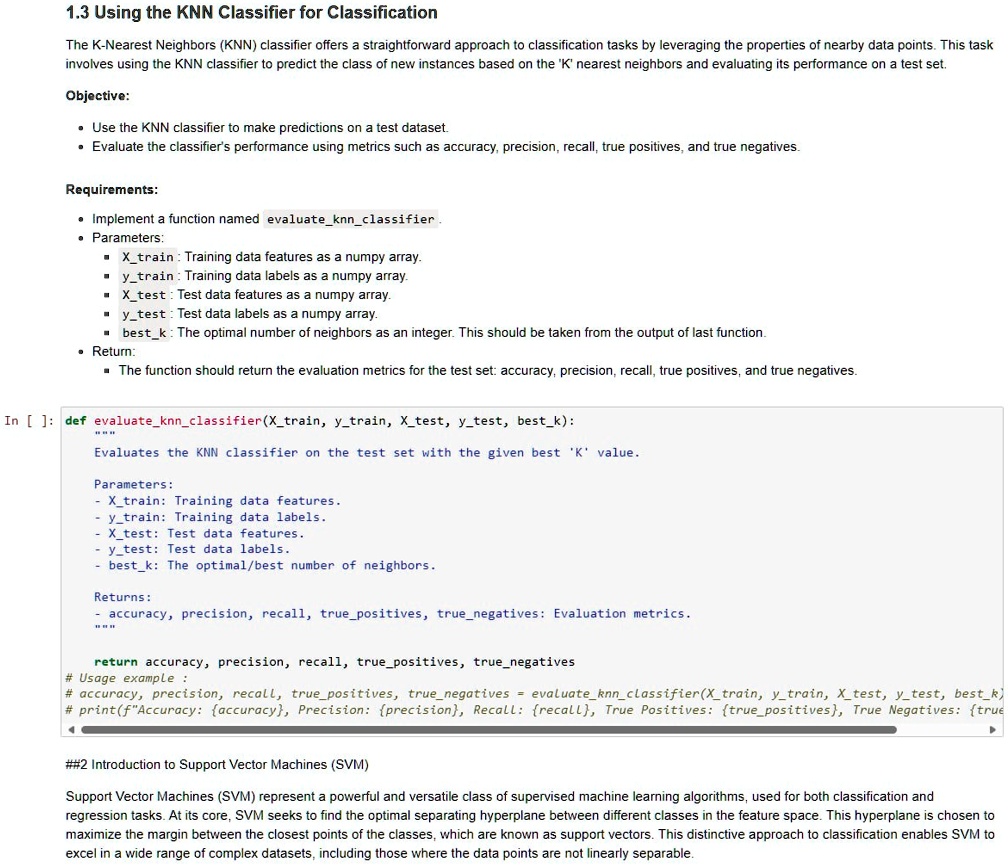
1.3 Using the KNN Classifier for Classification
The K-Nearest Neighbors (KNN) classifier offers a straightforward approach to classification tasks by leveraging the properties of nearby data points. This task involves using the KNN classifier to predict the class of new instances based on the 'K' nearest neighbors and evaluating its performance on a test set.
Objective:
Use the KNN classifier to make predictions on a test dataset. Evaluate the classifier's performance using metrics such as accuracy, precision, recall, true positives, and true negatives.
Requirements:
Implement a function named evaluate_knn_classifier. Parameters: X_train: Training data features as a numpy array. y_train: Training data labels as a numpy array. X_test: Test data features as a numpy array. y_test: Test data labels as a numpy array. best_k: The optimal number of neighbors as an integer. This should be taken from the output of the last function. Return: The function should return the evaluation metrics for the test set: accuracy, precision, recall, true positives, and true negatives.
In [ ]: def evaluate_knn_classifier(X_train, y_train, X_test, y_test, best_k):
Evaluates the KNN classifier on the test set with the given best 'K' value.
Parameters: - X_train: Training data features. - y_train: Training data labels. - X_test: Test data features. - y_test: Test data labels. - best_k: The optimal/best number of neighbors.
Returns: accuracy, precision, recall, true_positives, true_negatives: Evaluation metrics.
return accuracy, precision, recall, true_positives, true_negatives # Usage example: # accuracy, precision, recall, true_positives, true_negatives = evaluate_knn_classifier(X_train, y_train, X_test, y_test, best_k) # print(f"Accuracy: {accuracy}, Precision: {precision}, Recall: {recall}, True Positives: {true_positives}, True Negatives: {true}
##2 Introduction to Support Vector Machines (SVM)
Support Vector Machines (SVM) represent a powerful and versatile class of supervised machine learning algorithms, used for both classification and regression tasks. At its core, SVM seeks to find the optimal separating hyperplane between different classes in the feature space. This hyperplane is chosen to maximize the margin between the closest points of the classes, which are known as support vectors. This distinctive approach to classification enables SVM to excel in a wide range of complex datasets, including those where the data points are not linearly separable.